This documentation is also available as multiple HTML pages.
1. Setup Tai-e in IntelliJ IDEA
Given the Gradle build script, setting up Tai-e in IntelliJ IDEA is easy as explained below.
1.1. Step 0
Download IntelliJ IDEA from JetBrains. and install it. We recommend installing a recent version (2021.3 or newer) of IntelliJ IDEA for better support of Java 17.
1.2. Step 1
Start to open a project
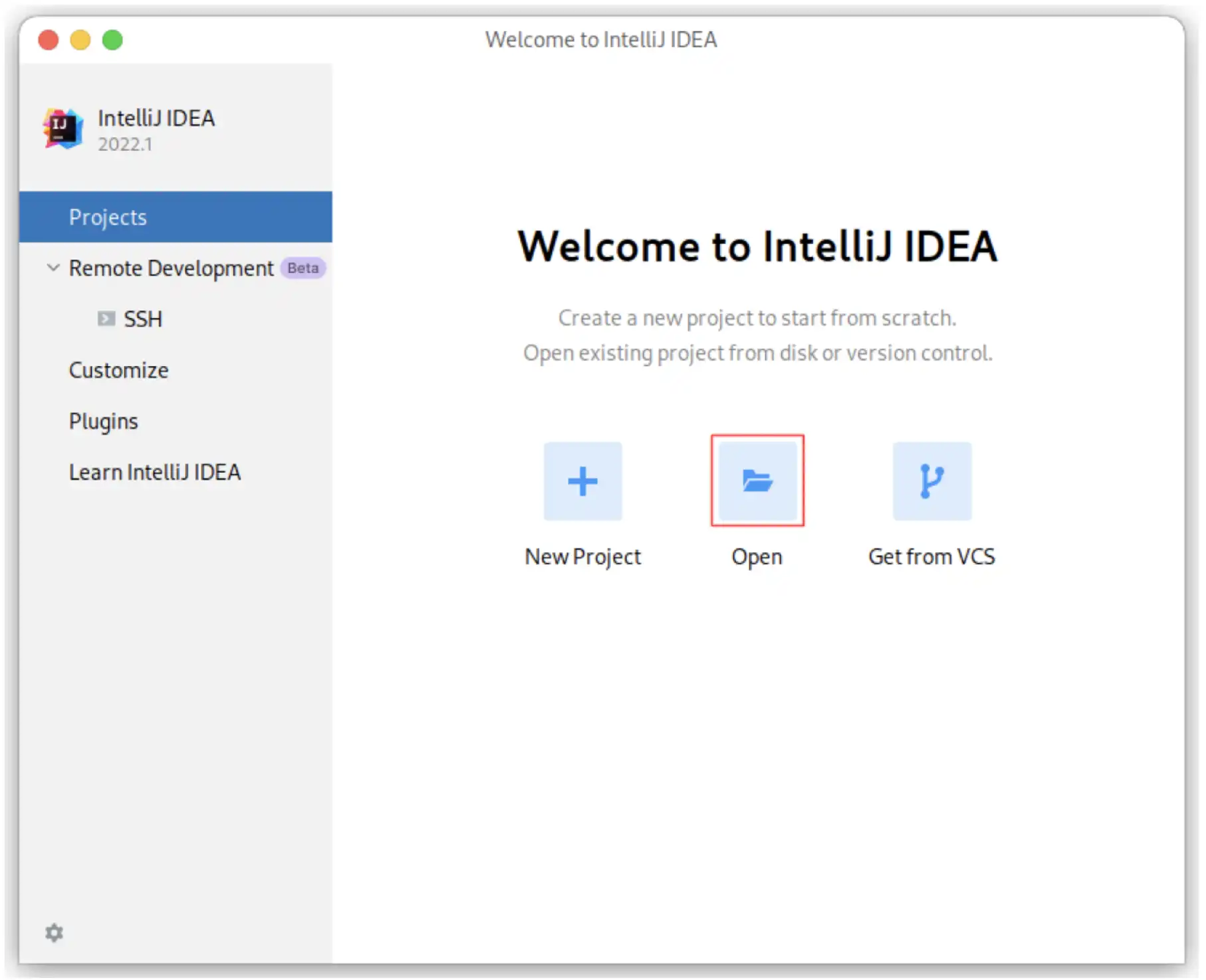
Note: If you have already used IntelliJ IDEA, and opened some projects, then you could choose
File > Open…to open the same dialog for the next step.
1.4. Step 3
IntelliJ IDEA may pop up a dialog asking if you trust the Gradle project. Just click "Trust Project" (Don’t worry. Tai-e is benign 😃).
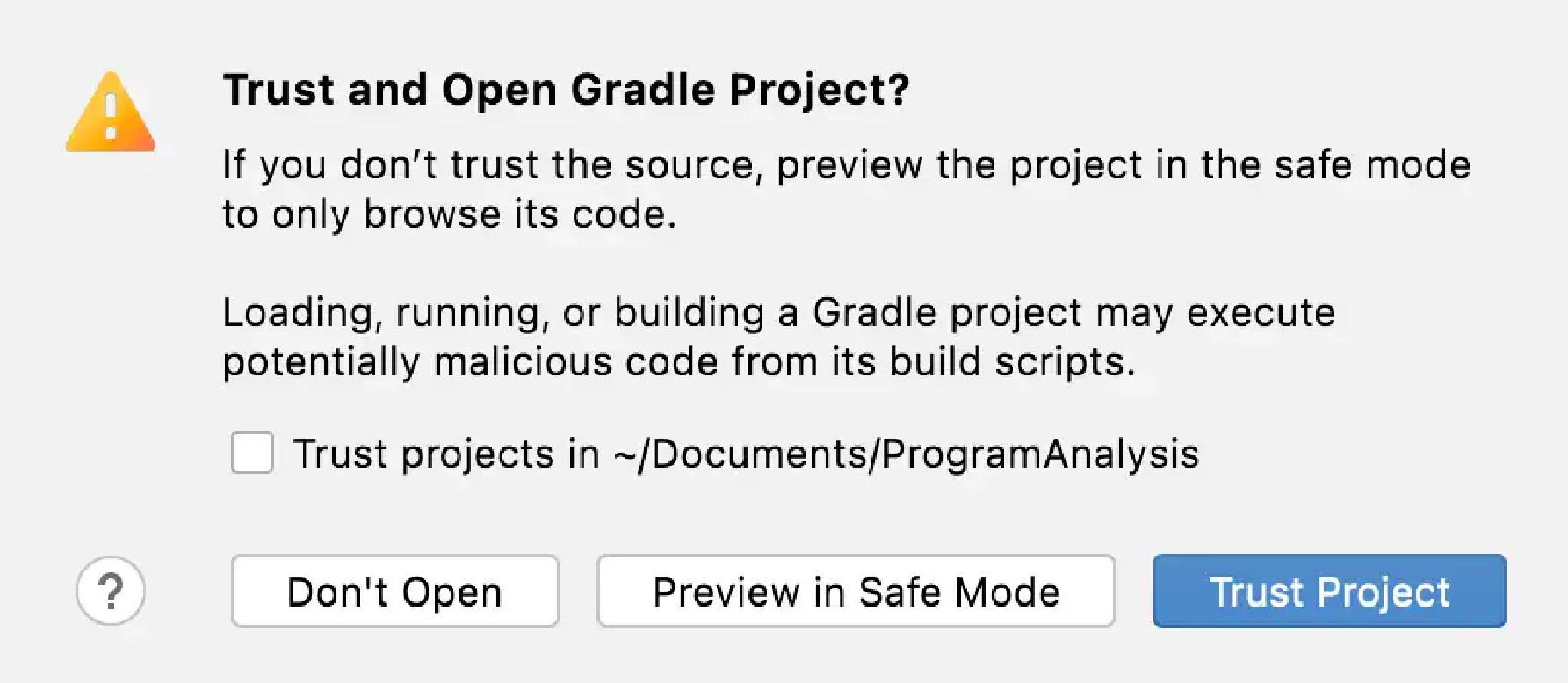
You may wait a moment for importing Tai-e.
1.5. Step 4
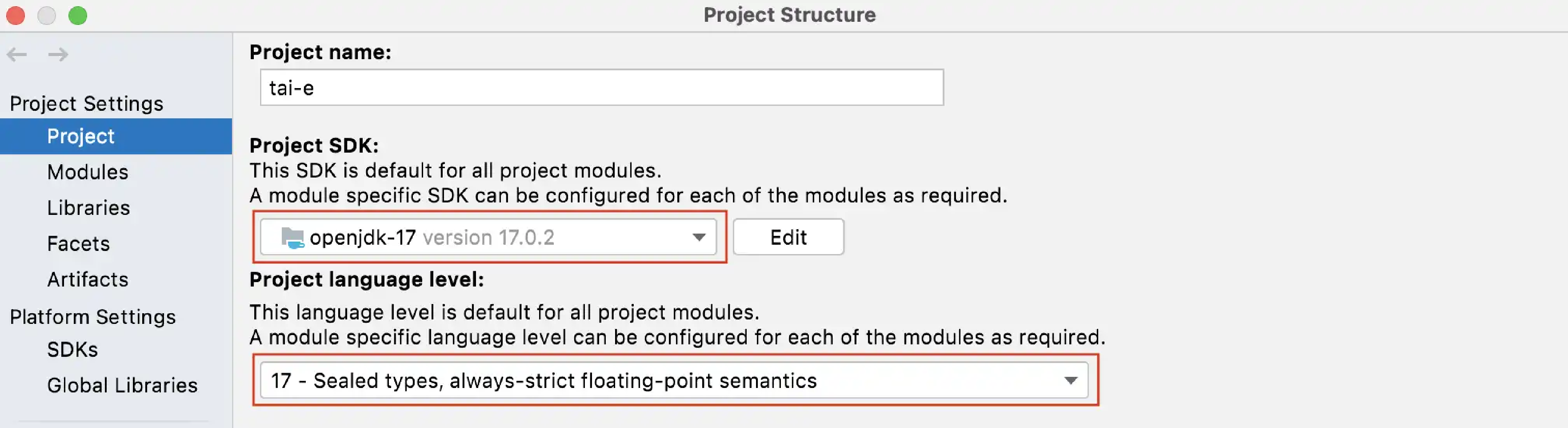
Go to File > Project Structure…, click "Project SDK", select JDK 17. Next, expand "Language level", select "SDK default" (if the default is just 17) or "17 - Sealed types, always-strict floating-point semantics":
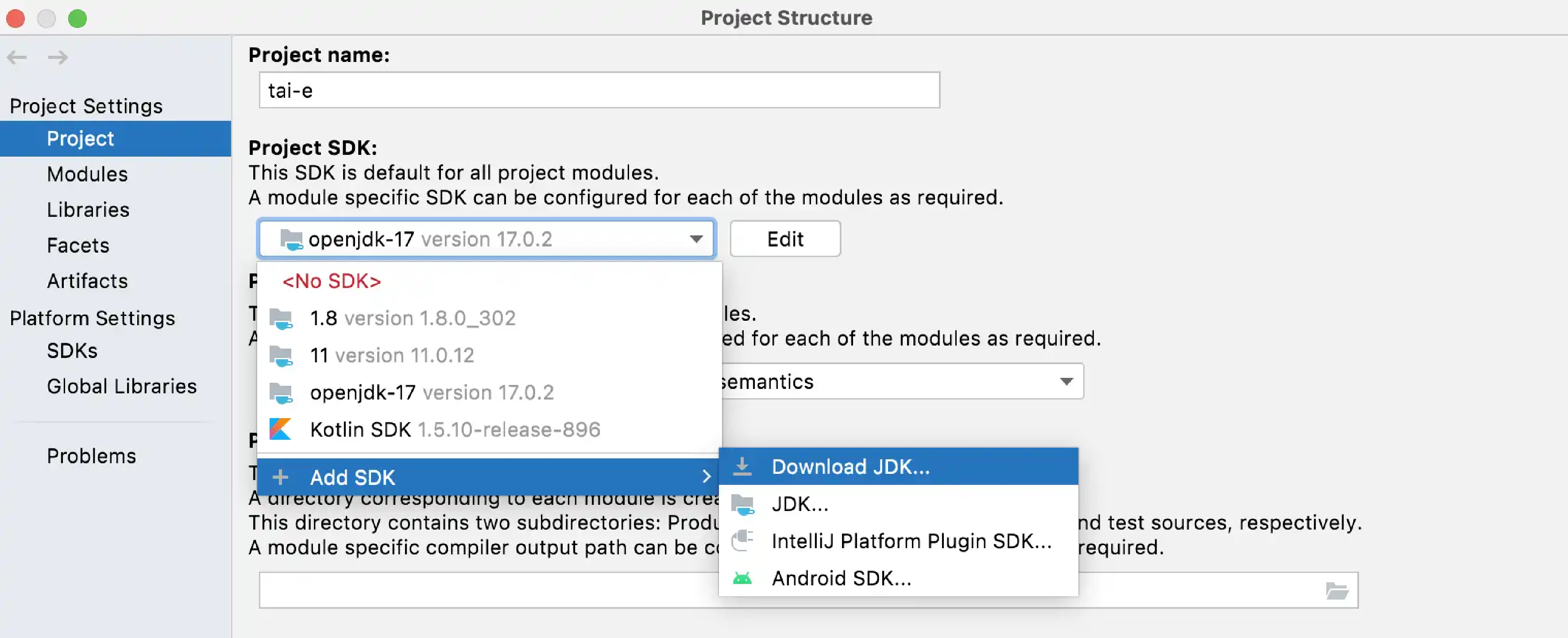
Note: If you have not installed JDK 17 yet, just select
Add SDK > Download JDK…, and select "17" for "Version", any "Vendor" (usually "Oracle OpenJDK"), and "Location" to be installation location (default is fine), and then click "Download" to start downloading in background:
1.6. Step 5 (optional)
As Tai-e is a Gradle project, IntelliJ IDEA always build and run it with Gradle by default, which makes it a bit slower and always output some annoying Gradle-related messages:
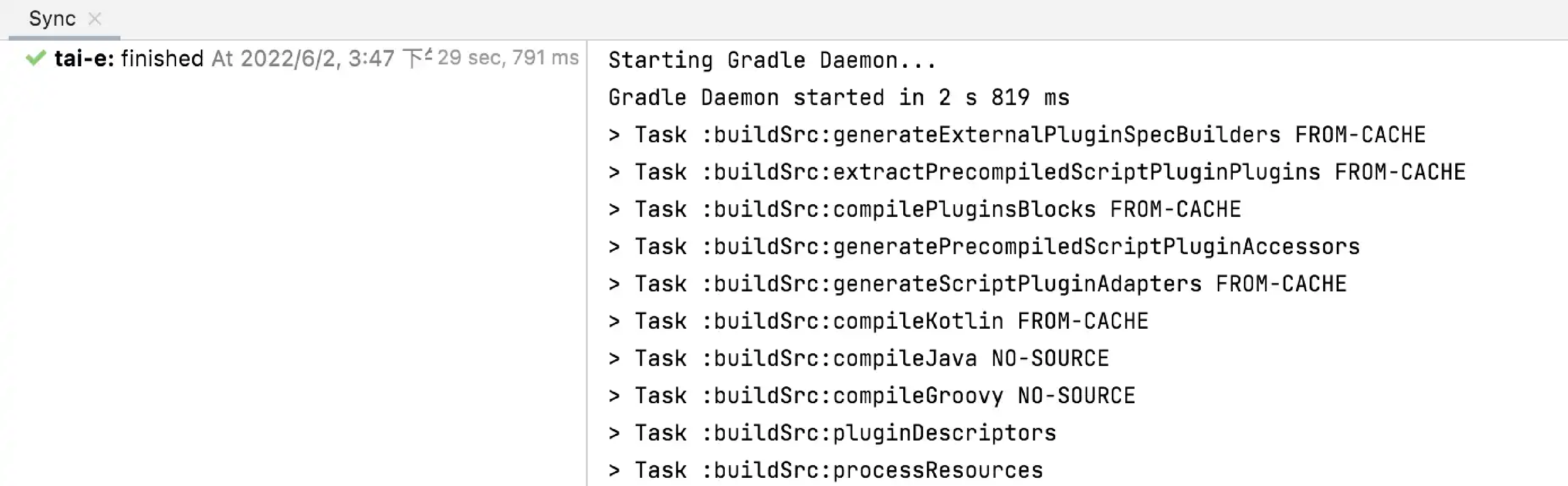
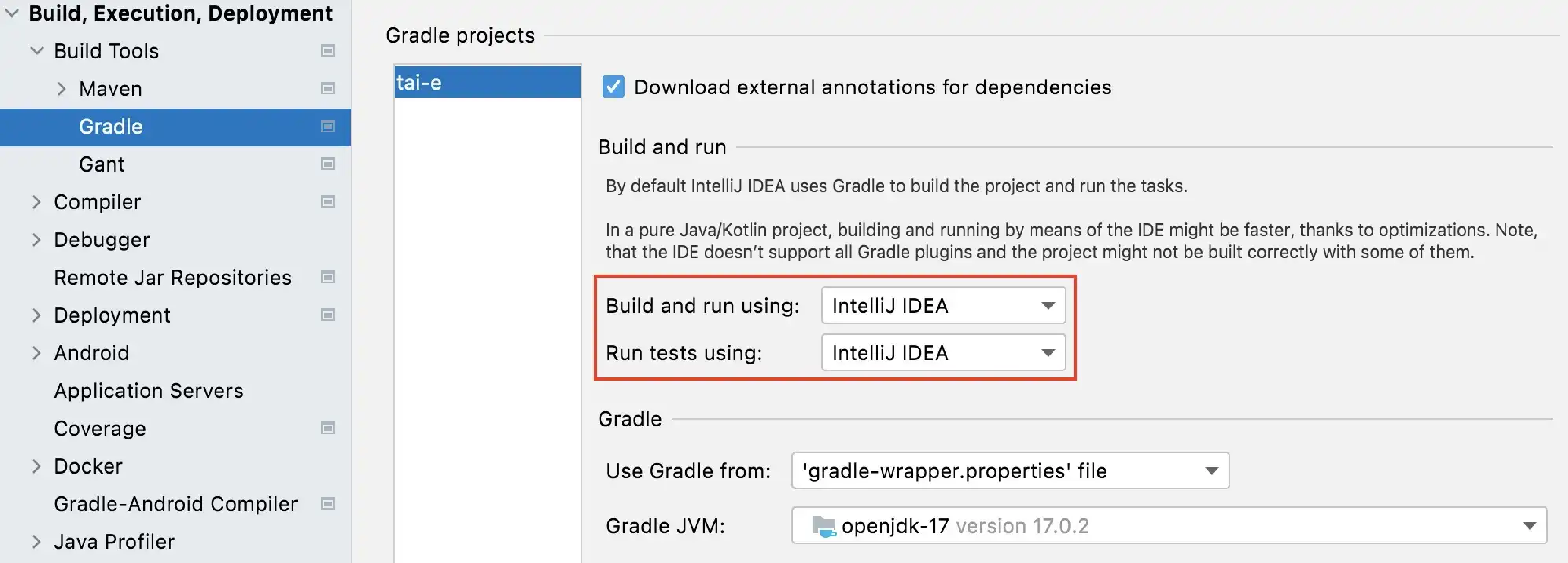
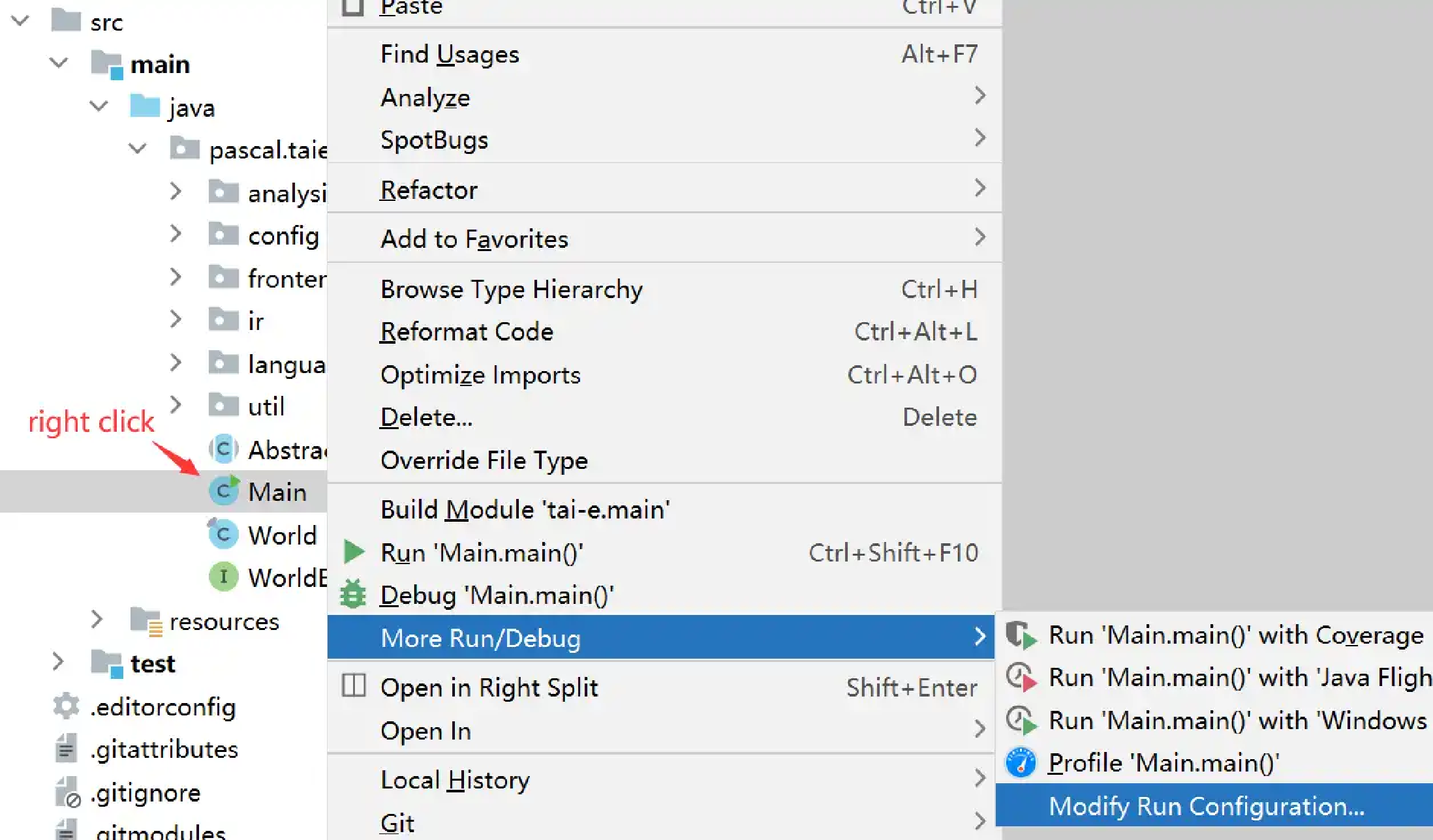
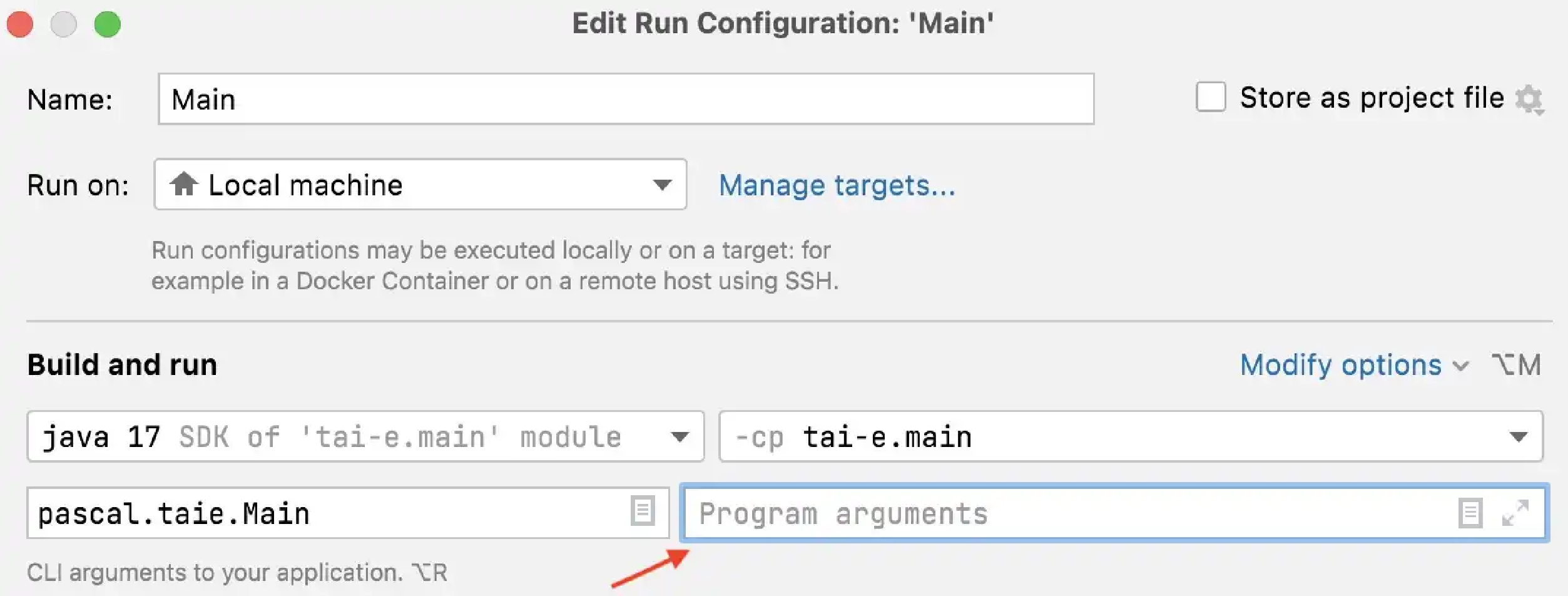
To get rid of these problems, you could use IntelliJ IDEA instead of Gradle to build and run Tai-e. Just go to File > Settings, and change the build and run tool from Gradle to IntelliJ IDEA:
2. How to Run Tai-e (command-line options)?
2.1. Prerequisites
Before running Tai-e, please finish following steps:
-
Install Java 17 (or higher version) on your system (Tai-e is developed in Java, and it runs on all major operating systems including Windows/Linux/macOS).
-
Clone submodule
java-benchmarks(this repo contains the Java libraries used by the analysis; it is large and may take a while to clone):
git submodule update --init --recursiveThe main class (entry) of Tai-e is pascal.taie.Main, and we classified its options into three categories:
-
Program options: specifying the program to analyze.
-
Analysis options: specifying the analyses to execute.
-
Other options
Below we introduce these options.
2.2. Program Options
These options specify the Java program (say P) and library to be analyzed.
Currently, Tai-e leverages Soot frontend to parse Java programs and help build Tai-e’s IR. Soot contains two frontends, one for parsing Java source files (.java) and the other one for bytecode files (.class). The former is outdated (only partially supports Java versions up to 7); while the latter, though quite robust (works properly for the .class files compiled by up to Java 17), cannot fully satisfy our requirements. Hence, we plan to develop our own frontend for Tai-e to address the above issues. For now, we advice using Tai-e to analyze bytecode, instead of source code, if possible.
-
Class paths (-cp, --class-path):
-cp <path>[:<path>…]-
Class paths for Tai-e to locate the classes of P, and multiple paths are separated by
;. Currently, Tai-e supports following types of paths:-
Relative/Absolute path to a jar file
-
Relative/Absolute path to a directory which contains
.class(or.java) files
-
-
Note that the path separator varies on different systems: it is
:on Unix-like systems, and;on Windows.
-
Application class paths (-acp, --app-class-path):
-acp <path>[:<path>…]-
Class paths for Tai-e to locate the application classes of P. The usage of this option is exactly the same as
-cp. -
The difference between
-cpand-acpis that for the classes in-cp, only the ones referenced by the application/main/input classes are added to the closed world of P; but all classes in-acpwill be added to the closed world.
-
-
Main class (-m, --main-class):
-m <main-class>-
The main class (entry) of P. This class must declare a method with signature
public static void main(String[]).
-
-
Input classes (--input-classes):
--input-classes=<inputClass>[,<inputClass>…]-
Add classes to the closed world of P. Some Java programs use dynamic class loading so that Tai-e cannot reference to the relevant classes from the main class. Such classes can be added to the closed world by this option.
-
The
<inputClass>should follow the format of fully-qualified name in Java, e.g.,org.package.MyClass.
-
-
Java version (-java):
-java <version>-
Default value: 6
-
Specify the version of Java library used in the analyses. When this option is given, Tai-e will locate the corresponding Java library in submodule
java-benchmarksand add it to the class paths. Currently, we provide libraries for Java versions 3, 4, 5, 6, 7, and 8. Support for newer Java versions is under development.
-
-
Prepend JVM Class Path (-pp, --prepend-JVM)
-
Prepend the class path of the JVM (which runs Tai-e) to the analysis class path. This means that if you run Tai-e with Java 17, then you can use Tai-e to analyze the library of Java 17. Note that this option will disable
-javaoption.
-
-
Allow phantom references (-ap, --allow-phantom)
-
Allow Tai-e to process phantom references, i.e., the referenced classes that are not found in the class paths.
-
2.3. Analysis Options
These options decide the analyses to be executed and their behaviors. We divided these options into two groups: general analysis options which affect multiple analyses, and specific analysis options which are relevant to individual analysis.
2.3.1. General Analysis Options
-
Build IR in advance (--pre-build-ir)
-
Build IRs for all available methods before starting any analyses.
-
-
Analysis scope (-scope):
-scope <scope>-
Default value:
APP -
Specify the analysis scope for class and method analyses.There are three valid choices:
-
APP: application classes only -
ALL: all classes -
REACHABLE: classes that are reachable in the call graph (this scope requires analysiscg, i.e., call graph construction)
-
-
2.3.2. Specific Analysis Options
To execute an analysis, you need to specify its id and options (if necessary). All available analyses in Tai-e and their information (e.g., id and available options) are listed in the analysis configuration file src/main/resources/tai-e-analyses.yml.
There are two mutually-exclusive approaches to specify the analyses, by command-line options or by file, as described below.
Analyses (-a, --analysis): -a <id>[=<key>:<value>;…]
Specify analyses by command-line options. For running analysis with id A, just give -a A. For specifying some analysis options for A, just append them to analysis id (connected by =), and separate them by ;, for example:
-a A=enableX:true;threshold:100;log-level:infoNote that on Unix-like systems (e.g., Linux), you may need to quote the option values when they include
;, for example:
-a "A=enableX:true;threshold:100;log-level:info"The option system is expressive, and it supports various types of option values, such as boolean, string, integer, and list.
Option -a is repeatable, so that if you need to execute multiple analyses in a single run of Tai-e, say A1 and A2, just repeat -a like: -a A1 -a A2.
Plan file (-p, --plan-file): -p <file-path>
Alternatively, you can specify the analyses to be executed (called an analysis plan) in a plan file, and use -p to process the file. Similar to -a, you need to specify the id and options (if necessary) for each analysis in the file. The plan file should be written in YAML.
Note that options -a and -p are mutually-exclusive, thus you cannot specify them simultaneously. See Analysis Management for more information about these two options.
Keep results of specific analyses (-kr, --keep-result): -kr <id>[,<id>…]
By default, Tai-e keeps results of all executed analyses in memory. If you run multiple analyses and care about the results of only some of them, you could use this option to specify these analyses, then every time Tai-e executes an analysis, it will automatically detect and clean the analysis results which are not used by subsequent analyses to save memory.
2.4. Other Options
-
Help (-h, --help)
-
Print help information for all available options. This option will disable all other given options.
-
-
Options file (--options-file):
--options-file <optionsFile>-
You can specify the command-line options in a file and use
--options-fileto process the file. When this option is given, Tai-e ignores all other command-line options, and only processes the options in the file. The options file should be written in YAML. -
Tai-e will output all options to
output/options.ymlat each run if this option is not given.
-
-
Generate plan file (-g, --gen-plan-file)
-
Merely generate analysis plan file (the plan will not be executed) to
output/tai-e-plan.yml. -
This option works only when the analysis plan is specified by option
-a, and it is provided to help the user compose analysis plan file.
-
-
World cache mode (-wc, --world-cache-mode)
-
Enable world cache mode to save build time by caching the completed built world to the disk.
-
When enabled, it will attempt to load the cached world instead of rebuilding it from scratch, provided that the analyzed program (i.e. classPath, mainClass and so on) remain unchanged. This option is particularly useful during development, when the analyzed program remains the same, but the analyzer code is modified and run repeatedly, thus saving developers' valuable time.
-
2.5. A Usage Example of Command-Line Options
We give an example of how to analyze a program by Tai-e. Suppose we want to analyze a program P as described below:
-
P consists of two jar files:
foo.jarandbar.jar -
P's main class is
baz.Main -
P is analyzed together with Java 8
-
we run 2-type-sensitive pointer analysis and limit the execution time of pointer analysis to 60 seconds
Then the options would be:
java -cp tai-e-all.jar pascal.taie.Main -cp foo.jar;bar.jar -m baz.Main -java 8 -a pta=cs:2-type;time-limit:603. How to Use Taint Analysis?
Tai-e provides a configurable and powerful taint analysis for detecting security vulnerabilities. We develop taint analysis based on the pointer analysis framework, enabling it to leverage advanced techniques (including various context sensitivity and heap abstraction techniques) and implementations (including the handling of complex language features such as reflection and lambda functions) provided by the pointer analysis framework. This documentation is dedicated to providing guidance on using our taint analysis.
3.1. Enabling Taint Analysis
In Tai-e, taint analysis is designed and implemented as a plugin of pointer analysis framework.
To enable taint analysis, simply start pointer analysis with option taint-config, for example:
-a pta=...;taint-config:<path/to/config>;...then Tai-e will run taint analysis (together with pointer analysis) using a configuration file specified by <path/to/config> (if you need to specify multiple configuration files, please refer to Multiple Configuration Files).
In the upcoming section, we will provide a comprehensive guide on crafting a configuration file.
| You could use various pointer analysis techniques to obtain different precision/efficiency tradeoffs. For additional details, please refer to Pointer Analysis Framework. |
3.2. Configuring Taint Analysis
In this section, we present instructions on configuring sources, sinks, taint transfers, and sanitizers for the taint analysis using a YAML configuration file. To get a broad understanding, you can start by examining the taint-config.yml file from our test cases as an illustrative example.
Certain configuration values include special characters, such as spaces, [, and ].
To ensure these values are correctly interpreted by the YAML parser, please make sure to enclose them within quotation marks.
|
3.2.1. Basic Concepts
We first present several basic concepts employed in the configuration.
Type
You may write following types in configuration:
| Type | Format | Examples |
|---|---|---|
Class type |
Fully-qualified class name. |
|
Array type |
A type following by one or more |
|
Primitive type |
Primitive type names in Java. |
|
Method Signature
In the configuration, we employ a method signature to provide a unique identifier for a method in the analyzed program. The format of a method signature is given below:
<CLASS_TYPE: RETURN_TYPE METHOD_NAME(PARAMETER_TYPES)>-
CLASS_TYPE: The class in which the method is declared. -
RETURN_TYPE: The return type of the method. -
METHOD_NAME: The name of the method. -
PARAMETER_TYPES: The list of parameters types of the method. Multiple parameter types are separated by,(Do not insert spaces around,!). If the method has no parameters, just write().
For example, the signatures of methods equals and toString of Object are:
<java.lang.Object: boolean equals(java.lang.Object)>
<java.lang.Object: java.lang.String toString()>Field Signature
Just like methods, field signatures serve the purpose of uniquely identifying fields within the analyzed program. The format of a field signature is given below:
<CLASS_TYPE: FIELD_TYPE FIELD_NAME>-
CLASS_TYPE: The class in which the field is declared. -
FIELD_TYPE: The type of the field. -
FIELD_NAME: The name of the field.
For example, the signature of the field info below
package org.example;
class MyClass {
String info;
}
is
<org.example.MyClass: java.lang.String info>Variable Index
When setting up taint analysis, it’s typically necessary to indicate a variable at a call site or within a method. This can be accomplished using variable index.
Variable Index of A Call Site
We classify variables at a call site into several kinds, and provide their corresponding indexes below:
| Kind | Description | Index |
|---|---|---|
Result variable |
The variable that receives the result of the method call, also known as the left-hand side (LHS) variable of the call site. |
|
Base variable |
The variable that points to the receiver object of the method call. Note that this variable is absent in the cases of static method calls. |
|
Arguments |
The arguments of the call site, indexed starting from 0. |
|
For example, for a method call
r = o.foo(p, q);
-
The index of variable
risresult. -
The index of variable
oisbase. -
The indexes of variables
pandqare0and1.
Variable Index of A Method
Currently, we support specifying parameters of a method using indexes.
Similar to arguments of a call site, the parameters are indexed starting from 0.
For example, the indexes of parameters t, s, and o of method foo below are 0, 1, and 2.
package org.example;
class MyClass {
void foo(T t, String s, Object o) {
...
}
}
3.2.2. Sources
Taint objects are generated by sources.
In the configuration file, sources are specified as a list of source entries following key sources, for example:
sources:
- { kind: call, method: "<javax.servlet.ServletRequestWrapper: java.lang.String getParameter(java.lang.String)>", index: result }
- { kind: param, method: "<com.example.Controller: java.lang.String index(javax.servlet.http.HttpServletRequest)>", index: 0 }
- { kind: field, field: "<SourceSink: java.lang.String info>" }Our taint analysis supports several kinds of sources, as introduced in the next sections.
Call Sources
This should be the most-commonly used source kind, for the cases that the taint objects are generated at call sites. The format of this kind of sources is:
- { kind: call, method: METHOD_SIGNATURE, index: INDEX, type: TYPE }If you write such a source in the configuration, then when the taint analysis finds that method METHOD_SIGNATURE is invoked at call site l, it will generate a taint object of type TYPE for the variable indicated by INDEX at call site l.
For how to specify METHOD_SIGNATURE and INDEX, please refer to Method Signature and Variable Index of A Call Site.
We use underlining to emphasize the optional nature of type: TYPE in call source configuration.
When it is not specified, the taint analysis will utilize the corresponding declared type from the method.
This includes using the return type for the result variable, the declaring class type for the base variable, and the parameter types for arguments as the type for the generated taint object.
Someone may wonder why we need to include type: TYPE in the configuration for taint objects when we can already obtain the declared type from the method.
This is because the type of taint objects should align with the corresponding actual objects.
However, in certain situations, the actual object type related to the method might be a subclass of the declared type.
Therefore, we use type: TYPE to specify the precise object type in such cases.
As an illustration, consider the code snippet below.
In this snippet, the source method Z.source() declares its return type as X, but it actually returns an object of type Y, which is a subclass of X.
Therefore, we can define type: Y for the taint object generated by Z.source() method.
|
class X {...}
class Y extends X { ... }
class Z {
X source() {
...
return new Y();
}
}
Throughout the rest of this documentation, we will also use underlining to indicate optional elements.
The reasons for specifying type: TYPE in other cases are similar to those for call sources.
In these situations, the type of generated taint object may be a subclass of the corresponding declared type.
|
Parameter Sources
Certain methods, such as entry methods, do not have explicit call sites within the program, making it impossible to generate taint objects for variables at their call sites. Nevertheless, there are situations where generating taint objects for their parameters can be useful. To address this requirement, our taint analysis provides the capability to configure parameter sources:
- { kind: param, method: METHOD_SIGNATURE, index: INDEX, type: TYPE }If you include this type of source in the configuration, when the taint analysis determines that the method METHOD_SIGNATURE is reachable, it will create a taint object of TYPE for the parameter indicated by INDEX.
For guidance on specifying METHOD_SIGNATURE and INDEX, please refer to the Method Signature and Variable Index of A Method.
Field Sources
Our taint analysis also enables users to designate fields as taint sources using the following format:
- { kind: field, field: FIELD_SIGNATURE, type: TYPE }When you include this type of source in the configuration, if the taint analysis identifies that the field FIELD_SIGNATURE is loaded into a variable v (e.g., v = o.f), it will generate a taint object of TYPE for v.
For instructions on specifying FIELD_SIGNATURE, please refer to Field Signature.
3.2.3. Sinks
At present, our taint analysis supports specifying specific variables at call sites of sink methods as sinks.
In the configuration file, sinks are defined as a list of sink entries under the key sinks:
sinks:
- { method: METHOD_SIGNATURE, index: INDEX }
- ...If you include this type of sink in the configuration, when the taint analysis identifies that the method METHOD_SIGNATURE is invoked at call site l and the variable at l, as indicated by INDEX, points to any taint objects, it will generate reports for the detected taint flows.
For guidance on specifying METHOD_SIGNATURE and INDEX, please refer to Method Signature and Variable Index of A Method.
3.2.4. Taint Transfers
In taint analysis, taint is associated with the data’s content, allowing it to move between objects. This process is referred to as taint transfer, and it occurs frequently in real-world code. If not managed effectively, the failure to address these transfers can result in the oversight of numerous security vulnerabilities.
Introduction
Here, we utilize an example to demonstrate the concept of taint transfer and its impact on taint analysis.
1
2
3
4
5
6
7
String taint = getSecret(); // source
StringBuilder sb = new StringBuilder();
sb.append("abc");
sb.append(taint); // taint is transferred to sb
sb.append("xyz");
String s = sb.toString(); // taint is transferred to s
leak(s); // sink
Suppose we consider getSecret() as the source and leak() as the sink.
In this scenario, the code at line 1 acquires secret data in the form of a string and stores it in the variable taint.
This secret data eventually flows to the sink at line 7 through two taint transfers:
-
The method call to
append()at line 4 adds the contents oftainttosb, resulting in theStringBuilderobject pointed to bysbcontaining the secret data. Therefore, it should also be regarded as tainted data. In essence, theappend()call at line 4 transfers taint fromtainttosb. -
The method call to
toString()at line 6 converts theStringBuilderto aString, which holds the same content as theStringBuilder, including the secret data. In essence,toString()transfers taint fromsbtos.
In this example, if the taint analysis fails to propagate taint from taint to sb and from sb to s, it will be unable to detect the privacy leakage.
To address such scenarios, our taint analysis allows users to specify which methods trigger taint transfers, facilitating the appropriate propagation of taint flow.
Configuration
In this section, we provide instructions on configuring taint transfers.
Taint transfer essentially involves the triggering of taint propagation from specific variables to other variables at call sites through method calls.
We refer to the source of taint transfer as the from-variable and the target as the to-variable.
For example, in the case of sb.append(taint) from the previous example, taint serves as the from-variable, and sb acts as the to-variable.
In the configuration file, taint transfers are defined as a list of transfer entries under the key transfers, as shown in the example below:
transfers:
- { method: "<java.lang.StringBuilder: java.lang.StringBuilder append(java.lang.String)>", from: 0, to: base }
- { method: "<java.lang.StringBuilder: java.lang.String toString()>", from: base, to: result }which can handle the taint transfers of the example in Introduction. Each transfer entry follows this format:
- { method: METHOD_SIGNATURE, from: INDEX, to: INDEX, type: TYPE }Here, METHOD_SIGNATURE represents the method that triggers taint transfer, from and to specify the indexes of from-variable and to-variable at the call site.
TYPE denotes the type of the transferred taint object, which is also optional.
Taint transfer can be intricate in real-world programs.
To detect a broader range of security vulnerabilities, our taint analysis supports various types of taint transfers.
You can use different expressions for from and to in transfer entries to enable different types of taint transfers, as outlined below:
| Transfer | From | To |
|---|---|---|
variable → variable |
|
|
variable → array |
|
|
variable → field |
|
|
array → variable |
|
|
field → variable |
|
|
As a reference, we use an example here to show usefulness of array → variable transfer.
1
2
3
4
String cmd = request.getParameter("cmd"); // source
Object[] cmds = new Object[]{cmd};
Expression expr = Factory.newExpression(cmds); // taint transfer: cmds[0] -> expr
execute(expr); // sink
Here, assuming we consider getParameter() as the source and execute() as the sink, the code retrieves a value from an HTTP request at line 1 (which is uncontrollable and thus treated as a source) and stores it in cmd.
At line 2, cmd is stored in an Object array, which is then used to create an Expression at line 3.
Finally, the Expression is passed to execute(), which might lead to a command injection.
To detect this injection, we need to propagate taint from cmd to expr when analyzing method call expr = Factory.newExpression(cmds).
At this call, the taint stored in array cmds is transferred to expr, and we can capture this behavior by specifying the following taint transfer entry:
- { method: "<Factory: Expression newExpression(java.lang.Object[])>", from: "0[*]", to: result }Here, from: "0[*]" indicates that the taint analysis will examine all elements in the array pointed to by 0-th parameter (i.e., cmds), and if it detects any taint objects, it will propagate them to the variable specified by to: result (i.e., expr).
[ and ] are special characters in YAML, so you need to enclose them in quotes like "0[*]".
|
3.2.5. Sanitizers
Our taint analysis allows users to define sanitizers in order to reduce false positives.
This can be accomplished by writing a list of sanitizer entries under the key sanitizers in the configuration, as demonstrated below:
sanitizers:
- { kind: param, method: METHOD_SIGNATURE, index: INDEX }
- ...Subsequently, the taint analysis will prevent the propagation of taint objects to the parameter specified by INDEX in the method METHOD_SIGNATURE.
3.2.6. Multiple Configuration Files
The taint analysis supports the loading of multiple configuration files, eliminating the need for users to consolidate all configurations into a single extensive file.
Users can simply place all relevant configuration files within a designated directory and then provide the path to this directory (<path/to/config>) when enabling the taint analysis.
| The taint analysis will traverse the directory iteratively during the configuration loading process. Therefore, you have the flexibility to organize the configuration files as you see fit, including placing them in multiple subdirectories if desired. |
3.3. Output of Taint Analysis
Currently, the output of the taint analysis consists of two parts: console output and taint flow graph.
3.3.1. Console Output
In console output, the taint analysis reports the detected taint flows using the following format:
Detected n taint flow(s):
TaintFlow{SOURCE_POINT -> SINK_POINT}
...Each taint flow is a pair of source point and sink point. A source point refers to a variable that points to a newly-generated taint object, while a sink point designates a variable pointing to taint objects that have flowed from the source point.
Given that there are several kinds of Sources, each kind has a corresponding source point representation with a specific format:
| Source | Source Point Description | Source Point Format | Explanation |
|---|---|---|---|
Call source |
A variable at a call site of the source method. |
|
|
Parameter source |
A parameter of the source method. |
|
|
Field source |
A variable that receives loaded value from the source field. |
|
|
The [i@Ln] represent the position of a statement, where i is the index of the statement in the IR, and n is the line number of the statement in the source code, which can help you locate the statement.
Here are some examples of source points for each kind:
-
Call source:
<Main: void main(java.lang.String[])>[3@L7] pw = invokestatic Data.getPassword()/result -
Parameter source:
<Controller: void doGet(javax.servlet.http.HttpServletRequest,javax.servlet.http.HttpServletResponse)>/0 -
Field source:
<Main: void main(java.lang.String[])> [29@L24] name = p.<Person: java.lang.String name>
The format of the sink point is exactly the same as call source point, so we won’t repeat the explanation here.
3.3.2. Taint Flow Graph
The console output only provides the starting and ending points of the taint flows. However, for users to validate the reported taint flows and associated security vulnerabilities, it is crucial to investigate the detailed propagation path of taint objects. To meet such needs, we define taint flow graph (TFG for short), whose nodes are the program pointers (e.g., variables and fields) that point to taint objects, and edges represent how taint objects flow among the pointers, so that users can check taint flows by going over the TFG.
To address this requirement, we introduce the concept of taint flow graph (TFG). In a TFG, nodes represent program pointers (such as variables and fields) that point to taint objects, while edges illustrate how taint objects move between these pointers. This allows users to review taint flows by analyzing the TFG.
Tai-e will output the path of the dumped TFG:
Dumping ...\tai-e\output\taint-flow-graph.dotTFG is dumped as a DOT graph. For a better experience, we recommend installing Graphviz and using it to convert DOT to SVG with the following command:
$ dot -Tsvg taint-flow-graph.dot -o taint-flow-graph.svgthen you can open the TFG with your web browser and examine it.
| We plan to develop more user-friendly mechanisms for examining taint analysis results in the future. |
4. How to Develop A New Analysis on Tai-e?
Tai-e is highly extensible. To develop a new analysis and make it available in Tai-e, you just need to follow the two steps below.
4.1. Step 1. Develop An Analysis
At first, you need to implement your analysis class, which should extend either MethodAnalysis, ClassAnalysis or ProgramAnalysis (all in package pascal.taie.analysis) depending on whether the analysis runs on method-, class- or program-level. When writing the analysis class, you need to:
-
Declare a public static field
IDof typeString, whose value is identical to the analysis id in the configuration file. -
Implement constructor with argument
AnalysisConfig, and pass it to the constructor of parent class. -
Implement the analysis logic in
analyze()method.-
For
MethodAnalysis, you need to implement methodanalyze(IR), which at each time takes the IR of a method as input. -
For
ClassAnalysis, you need to implement methodanalyze(JClass), which at each time takes a class as input. -
For
ProgramAnalysis, you need to implement methodanalyze(). Inter-procedural analyses typically require whole-program information, which can be accessed via the static methods ofWorld, thus we do not pass argument to theanalyze()method.
-
Note that above *Analysis classes are generic and the type parameter is identical to the type of analysis result, which is the return type of the corresponding analyze method, i.e., Tai-e assumes that return value of analyze is the analysis result (and manages results based on such assumption). Below we give some tips that may be useful for developing new analysis.
-
Get familiar with Tai-e: See Program Abstraction in Tai-e for more information about Tai-e, such as the important classes that you might use when writing new analysis.
-
Obtain options: Global options are available at
World.get().getOptions(); options with respect to each analysis are dispatched to eachAnalysisobject, and can be accessed bygetOptions()within the analysis class. -
Obtain results of dependent analyses: If your analysis requires the results of some other previously-executed analyses, you can obtain them by calling
ir.getResult(id),jclass.getResult(id), orWorld.get().getResult(id)for method/class/program-level results.
4.2. Step 2. Register the Analysis
To make an analysis available in Tai-e, you need to register it by adding its information (such as analysis id, analysis class, etc.) to the configuration file src/main/resources/tai-e-analyses.yml ("config file" for short), which contains the information of all available analyses. Please refer to Analysis Management for details about analysis registration.
After adding analysis information to config file, your analysis is now available in Tai-e.
4.3. An Example
We give a simple example to illustrate how to add a new analysis to Tai-e.
Suppose that we are going to implement an intra-procedural dead code detection, which requires CFG and the analysis results of live variable analysis and constant propagation. We choose to extend MethodAnalysis, and complete the required tasks as explained in Step 1 (we omit concrete analysis logic for simplicity):
package my.example;
public class DeadCodeDetection extends MethodAnalysis<Set<Stmt>> {
// declare field ID
public static final String ID = "my-deadcode";
// implement constructor
public DeadCodeDetection(AnalysisConfig config) {
super(config);
}
// implement analyze(IR) method
@Override
public Set<Stmt> analyze(IR ir) {
// obtain results of dependent analyses
CFG<Stmt> cfg = ir.getResult(CFGBuilder.ID);
NodeResult<Stmt, CPFact> constants = ir.getResult(ConstantPropagation.ID);
NodeResult<Stmt, SetFact<Var>> liveVars = ir.getResult(LiveVariable.ID);
// analysis logic
Set<Stmt> deadCode;
...
return deadCode;
}
}
Then we register the analysis by adding its information to src/main/resources/tai-e-analyses.yml (The analysis does not have options, thus we can ignore item options):
- description: dead code detection
analysisClass: my.example.DeadCodeDetection
id: my-deadcode
requires: [ cfg,constprop,livevar ]That’s it! Now you can run the dead code detection via option -a my-deadcode.
5. Program Abstraction in Tai-e (core classes and IR)
This document introduces Tai-e’s abstraction of the Java program being analyzed. You will likely need to use the classes introduced in this document when developing analyses on top of Tai-e. See Section 2 of Tai-e’s paper for more discussions.
5.1. Core Classes
-
JClass(inpascal.taie.language.classes) represents classes in the program. Each instance contains various information of a class, such as class name, modifiers, declared methods and fields, etc. -
JMethodandJField: (inpascal.taie.language.classes): represents class members, i.e., methods and fields in the program. EachJMethod/JFieldinstance contains various information of a method/field, such as declaring class, name, etc. -
ClassHierarchy(inpascal.taie.language.classes): manages all the classes of the program. It offers APIs to query class hierarchy information, such as method dispatching, subclass checking, etc. -
Type(inpascal.taie.language.type): represents types in the program. It has several subclasses, e.g.,PrimitiveType,ClassTyp, andArrayType, representing different kinds of Java types. -
TypeSystem(inpascal.taie.language.type): provides APIs for retrieving specific types and subtype checking. -
World(inpascal.taie): manages the whole-program information of the program. By using its getters, you can access these information, e.g.,ClassHierarchyandTypeSystem.Worldis essentially a singleton class, and you can obtain the instance by callingWorld.get().
5.2. Tai-e IR
Tai-e IR is typed, 3-address, statement and expression based representation of Java method body.
You could dump IR for the classes of input program to .tir files via option -a ir-dumper. By default, Tai-e dumps IR to its default output directory output/. If you want to dump IR to a specific directory, just use option -a ir-dumper=dump-dir:path/to/dir. ir-dumper is implemented as a class analysis, thus the scope of the classes it dumps are affected by option -scope.
The IR classes reside in package pascal.taie.ir and its sub-packages.
There are three core classes in Tai-e IR:
-
IRis the central data structure of intermediate representation in Tai-e, and each IR instance can be seen as a container of the information for the body of a particular method, such as variables, parameters, statements, etc. You could easily obtain IR instance of a method byJMethod.getIR()(providing the method is not abstract). -
Stmtrepresents all statements in the program. This interface has a dozen of subclasses, corresponding to various statements.Stmt`s are stored in `IR, and you could obtain them viaIR.getStmts(). -
Exprepresents all expressions in the program. This interface has dozens of subclasses, corresponding to various expressions.Exp`s are associated with `Stmt`s, and you could obtain them via specific APIs of `Stmt.
We believe that the API of IR is self-documenting and easy to use. To make IR more intelligible, we present a formal definition (i.e., context-free grammar) below that illustrates all kinds of expressions and statements in the IR, and how Stmt are formed by Exp. Most non-terminals in the grammar corresponds to classes in pascal.taie.ir.
5.2.1. Grammar of Expressions
Exp → Var | Literal | FieldAccess | ArrayAccess | NewExp | InvokeExp | UnaryExp | BinaryExp | InstanceOfExp | CastExp
-
Var → Identifier
-
Literal → IntLiteral | LongLiteral | FloatLiteral | DoubleLiteral | StringLiteral | ClassLiteral | NullLiteral | MethodHandle | MethodType
-
FieldAccess → InstanceFieldAccess | StaticFieldAccess
-
InstanceFieldAccess → Var.FieldRef
-
StaticFieldAccess → FieldRef
-
FieldRef → <ClassType: Type FieldName>
-
FieldName → Identifier
-
-
ArrayAccess → Var[Var]
-
NewExp → NewInstance | NewArray | NewMultiArray
-
NewInstance → new ClassType
-
NewArray → new Type[Var]
-
NewMultiArray → new Type LengthList EmptyList
-
LengthList → [Var] | [Var]LengthList
-
EmptyList → ε | []EmptyList
-
-
InvokeExp → InvokeVirtual | InvokeInterface | InvokeSpecial | InvokeStatic | InvokeDynamic
-
InvokeVirtual → invokevirtual Var.MethodRef(ArgList)
-
InvokeInterface → invokeinterface Var.MethodRef(ArgList)
-
InvokeSpecial → invokespecial Var.MethodRef(ArgList)
-
InvokeStatic → invokestatic MethodRef(ArgList)
-
InvokeDynamic → invokedynamic BootstrapMethodRef MethodName MethodType [BootstrapArgList] (ArgList)
-
MethodRef → <ClassType: Type MethodName(TypeList)>
-
MethodName → Identifier
-
TypeList → ε | Type TypeList'
-
TypeList' → ε | , Type TypeList'
-
ArgList → ε | Var ArgList'
-
ArgList' → ε | , Var ArgList'
-
BootstrapMethodRef → MethodRef
-
BootstrapArgList → ε | Literal BootstrapArgList'
-
BootstrapArgList' → ε | , Literal BootstrapArgList'
-
-
UnaryExp → NegExp | ArrayLengthExp
-
NegExp → !Var
-
ArrayLengthExp → Var.length
-
-
BinaryExp → ArithmeticExp | BitwiseExp | ComparisonExp | ConditionExp | ShiftExp
-
ArithmeticExp → Var ArithmeticOp Var
-
ArithmeticOp → + | - | * | / | %
-
BitwiseExp → Var BitwiseOp Var
-
BitwiseOp → "|" | & | ^
-
ComparisonExp → Var ComparisonOp Var
-
ComparisonOp → cmp | cmpl | cmpg
-
ConditionExp → Var ConditionOp Var
-
ConditionOp → == | != | < | > | ⇐ | >=
-
ShiftExp → Var ShiftOp Var
-
ShitOp → << | >> | >>>
-
-
InstanceOfExp → Var instanceof Type
-
CastExp → (Type) Var
5.2.2. Grammar of Statements
Stmt → AssignStmt | JumpStmt | Invoke | Return | Throw | Catch | Monitor | Nop
-
AssignStmt → New | AssignLiteral | Copy | LoadArray | StoreArray | LoadField | StoreField | Unary | Binary | InstanceOf | Cast
-
New → Var = NewExp;
-
AssignLiteral → Var = Literal;
-
Copy → Var = Var;
-
LoadArray → Var = ArrayAccess;
-
StoreArray → ArrayAccess = Var;
-
LoadField → Var = FieldAccess;
-
StoreField → FieldAccess = Var;
-
Unary → Var = UnaryExp;
-
Binary → Var = BinaryExp;
-
InstanceOf → Var = InstanceOfExp;
-
Cast → Var = CastExp;
-
-
JumpStmt → Goto | If | Switch
-
Goto → goto Label;
-
If → if ConditionExp goto Label;
-
Switch → TableSwitch | LookupSwitch
-
TableSwitch → tableswitch (Var) { CaseList default: goto Label; }
-
LookupSwitch → lookupswitch (Var) { CaseList default: goto Label; }
-
Label → IntLiteral
-
CaseList → ε | case IntLiteral: goto Label; CaseList
-
-
Invoke → InvokeExp; | Var = InvokeExp;
-
Return → return; | return Var;
-
Throw → throw Var;
-
Catch → catch Var;
-
Monitor → monitorenter Var; | monitorexit Var;
-
Nop → nop;
6. Analysis Management
It is very common for an analysis framework to conduct multiple analyses in a single run, e.g., user wants to run many bug detectors to find more bugs, or an analysis depends on the outcomes of other analyses. By design, Tai-e supports these scenarios via a systematic analysis management, as explained in this document.
6.1. Analysis Information Registration
As mentioned in Develop A New Analysis, to add a new analysis to Tai-e, one needs to register its information in analysis configuration file src/main/resources/tai-e-analyses.yml. Each analysis entry consists of five (or less) attributes:
-
description: a description of the analysisThis attribute is only for documenting purpose.
-
analysisClass: fully-qualified name of the analysis classTai-e loads the analysis classes based on this attribute.
-
id: a short and unique identifier of an analysisTai-e relies on this attribute identify each analysis, so each id must be unique.
-
requires(optional): a list of dependent analysesIf an analysis requires the results of any other analyses, then we can specify the ids of the dependent analyses in this attribute. At runtime, Tai-e automatically resolves analysis dependencies according to this attributes, ensuring the correctness of execution order for all dependent analyses; besides, this approach frees up developers to concentrate on the specification of their own analysis, and saves their efforts of writing command options when running an analysis.
Each item in
requiresattribute consists of two parts:-
Analysis id, e.g.,
A, whose result is required by this analysis. -
A boolean expression in parentheses (optional), e.g.,
(x=y), indicates that the specified analysis is required only when the expression value is true. The expression value is determined by the runtime values of the specified options, for examples:-
requires: [A(x=y)]: requiresAwhen runtime value of optionxisy -
requires: [A(x=y&a=b)]: requiresAwhen runtime value of optionxisyand runtime value of optionaisb -
requires: [A(x=a|b|c)]: requiresAwhen runtime value of optionxisa,b, orc
-
This feature makes Tai-e more flexible in resolving analysis dependencies. You don’t need to write this attribute for an independent analysis.
-
-
options[optional]: a map of default option values
This attribute allowing to specify default values for all options of the analysis. These values can be overwritten by runtime-specified option values. You don’t need to write this attribute if your analysis has no options.
You can see examples about analysis registration in Section 5.1 of our technical report and tai-e-analyses.yml.
6.2. Analysis Plan
At runtime, Tai-e first generates an analysis plan (essentially a list of analyses to be executed) based on tai-e-analyses.yml and runtime-provided option values, and then runs analyses in order according to the plan.
As described in Command-Line Options, there are two approaches to specify the analyses to execute. Next, we will explain how they affect the generated analysis plan.
6.2.1. By Command-Line Options (Option -a)
If you specify analyses, say A1,…,An, via option -a, Tai-e will resolve all analyses directly/indirectly required by A1,…,An, and generate an analysis plan (including all these analyses) by topological sorting.
6.2.2. By Plan File (Option -p)
Alternatively, you can specify analyses by a plan file, which is a YAML file consisting of a list of analysis entries. Each entry has two attributes:
-
id: the analysis to be executed. -
options: runtime option values for the analysis.
When using option -p, Tai-e will execute the analyses in strict accordance with the plan file, i.e., it neither resolve analysis dependencies nor sort the analyses, thus, the file should include all required analyses, and each analysis should be placed in front of all the other analyses that require it; otherwise, Tai-e will alert.
Composing a plan file from scratch might be tedious. To ease this task, Tai-e always generate a plan file output/tai-e-plan.yml each time you specify analyses with option -a, so that you can easily obtain a plan file and then edit your plan based on it. In addition, we provide auxiliary option -g (--gen-plan-file) and when you use it together with -a, Tai-e will merely generates plan file without actually running the analyses.
6.3. Analysis Result Management
Result management is important for the cases that an analysis requires the results of other analyses, which happen frequently. Depending on the type of analysis, Tai-e automatically stores the results in various locations:
-
For a method-level analysis, Tai-e stores its results in the
IR, i.e., argument ofMethodAnalysis.analyze(IR). -
For a class-level analysis, Tai-e stores its results in the
JClass, i.e., argument ofClassAnalysis.analyze(JClass). -
For a program-level analysis, Tai-e stores its results in
World.
Benefiting from the result management, the developers only need to remember one API, getResult(id) (id is identifier of the analysis), to obtain results of any types of analyses, e.g., ir.getResult(id) for method-level analysis, jclass.getResult(id) for class-level analysis, and world.getResult(id) for program-level analysis.
With aforementioned mechanisms, it is fairly simple to coordinate multiple analyses in Tai-e.
7. Pointer Analysis Framework
Pointer analysis is one the most important fundamental static analyses. Tai-e provides a versatile, efficient and extensible pointer analysis framework, which supports different kinds of heap abstraction and context sensitivity variants. It is able to produce more sound and faster pointer analyses than other pointer analysis frameworks, under both context-insensitive and context-sensitive settings (see Tai-e’s paper for more details).
A distinguishing feature of our pointer analysis framework is its analysis plugin system, which enables to conveniently develop and add new analyses (that need to interact with pointer analysis) to the framework in a modular manner and make it easier to maintain and extend. Currently, many analyses in Tai-e have been implemented as plugins of our pointer analysis framework, such as reflection analysis, lambda analysis, exception analysis, and taint analysis.
Below we introduce key options of pointer analysis and the analysis plugin system.
7.1. Options
The analysis id of pointer analysis is pta, and here we list its key options:
-
Context sensitivity:
cs:ci|k-[obj|type|call][-k’h]-
Default value:
ci(context insensitivity) -
Specify context sensitivity variant of the pointer analysis.It supports context insensitivity, and k-limiting object/type/call-site sensitivity, e.g.,
1-objand2-call.By default, the limit for heap contexts isk-1(the recommended one).If you want to specify other limit for heap contexts, sayk', just append-k’h, e.g.,2-type-2h.
-
-
Only analyze application code:
only-app:[true|false]-
Default value:
false -
When set to
true, the pointer analysis only analyzes application code (and ignores library code).
-
-
Implicit entries:
implicit-entries:[true|false]-
Default value:
true -
Specify whether to consider the methods that are called implicitly by the JVM as entry points of the pointer analysis.When it is
false, these methods are not considered as entry points, leading to a possibly unsound points-to result.
-
-
String constants:
distinguish-string-constants:<strategy>-
Default value:
reflection -
Specify which string constants to distinguish.Currently support the following strategies:
-
reflection: only distinguish reflection-relevant string constants, i.e., class, method, and field names. -
null: do not distinguish any string constants, i.e., merge all of them. -
all: distinguish all string constants. -
<predicate-class>: You could implement your strategy to distinguish string constants. In this case, just give fully-qualified name of your predicate class here. See IsReflectionString as an example.
-
-
-
Object merging:
merge-string-objects/merge-string-builder/merge-exception-objects:[true|false]-
Default value:
true. -
Specify whether to merge corresponding objects.
-
-
Advanced analysis:
advanced:<analysis>-
Default value:
null -
Enable advance pointer analysis technique.Currently, we have integrated following techniques:
-
Zipper-e (option value:
zipper-e): introduced in our TOPLAS'20 paper. -
Zipper (option value:
zipper): introduced in our OOPSLA'18 paper. -
Scaler (option value:
scaler): introduced in our FSE'18 paper. -
Mahjong (option value:
mahjong): introduced in our PLDI'17 paper.
-
-
-
Reflection log:
reflection-log:<path/to/log>-
Default value:
null -
Specify the path to reflection log file. For the reflective calls specified in the log file, pointer analysis will resolve them by their targets in the log file. (currently supports the output format of TamiFlex, and see ReflectiveAction.log as an example).
-
-
Reflection inference:
reflection-inference:<strategy>-
Default value:
string-constant. -
Specify strategy for static reflection inference.This option can work together with
reflection-log, and if the targets of a reflective call are given in the log, reflection inference will ignore the call.Currently support the following strategies:-
String constant based inference (option value:
string-constant): resolve reflective calls by string constants. -
Solar (option value:
solar): introduced in our TOSEM'19 paper. -
No inference (option value:
null): disable reflection inference.
-
-
-
Taint analysis:
taint-config:<path/to/config>-
Default value:
null -
Specify the path to configuration file for taint analysis, which defines sources, sinks, and taint transfers. Taint analysis will be enabled when this file is given. See Taint Analysis for more details.
-
-
Plugins:
plugins:[<pluginClass>,…]-
Default value:
[] -
Activate plugins.To enable a plugin, just add fully-qualified name of the plugin class to this list.
-
-
Dump points-to results (without context information):
dump-ci:[true|false]-
Default value:
false -
Specify whether to dump points-to results.
-
-
Dump points-to results (with context information):
dump:[true|false]-
Default value:
false -
Specify whether to dump points-to results.
-
-
Time limit:
time-limit:<time-limit>-
Default value:
-1 -
Specify a time limit for pointer analysis (unit: second).When it is
-1, there is no time limit.
-
7.2. Analysis Plugin System
We explain how this analysis plugin system works.As shown in figure below:

The analysis plugin system includes a pointer analysis solver (pascal.taie.analysis.pta.core.solver.Solver) and a number of analyses that communicate with it.Each of these analyses is referred to as an analysis plugin that needs to implement interface pascal.taie.analysis.pta.plugin.Plugin.The interactions between pointer analysis solver and analysis plugin are carried out by calling each other’s APIs of Solver and Plugin, which are highlighted in blue and red, respectively.The Solver APIs have been implemented in the framework, and developers only need to implement the related APIs of Plugin, which are invoked by Solver at different stages (e.g., initialization and finishing) or on different events (e.g., discovery of new points-to relations and call edges).The additional auxiliary APIs, e.g., Solver.addStmts() and Plugin.onNewMethod(), are optional and designed to make it easier to implement specific analysis logics.
Let us briefly illustrate the basic working mechanism that drives those core APIs.
Assuming you are implementing the onNewPointsToSet() method of an analysis Plugin, this means whenever an interested variable’s (parameter CSVar) points-to set (parameter PointsToSet) is changed (i.e., it points to more objects), you need to encode your logic to reflect the side effect made by this change; the final consequence of such an effect, from the perspective of pointer analysis, is to modify the points-to set of any related pointers or to add call graph edges at pertinent call sites.
Accordingly, you should call Solver.addPointsTo() or Solver.addCallEdge() to alert the solver of these modifications.
Conversely, during each analysis iteration, the solver calls Plugin.onNewPointsToSet() and Plugin.onNewCallEdge() of every plugin to notify them of any changes to the variables' points-to sets or call graph edges, respectively.
As a result, to add a new analysis that interacts with pointer analysis, developers just need to implement a few methods of Plugin in accordance with the requirement, as previously described.
This analysis plugin system is currently being used by a number of ongoing internal projects implemented by different developers (these projects will be released when finished), and the feedback from developers is very promising: everyone agrees that it can fulfill their practical needs and is simple to understand and apply.
For more details of the analysis plugin system, please see Section 4.1 of Tai-e’s paper and the source code (specifically, the interfaces Plugin and Solver, which are self-documenting).
7.3. An Example of Plugin
We use an example to illustrate how to develop a new analysis plugin and add it to the pointer analysis framework.For simplicity, we omit the concrete analysis logics in the example.
Suppose we are implementing a taint analysis that interacts with pointer analysis.It requires following steps.
-
Create a plugin class that implements
Plugininterface.package my.example; public class TaintAnalysis implements Plugin { -
Implement necessary APIs of
Pluginwith the analysis logics.private Solver solver; @Override public setSolver(Solver solver) { this.solver = solver; } @Override public void onNewCallEdge(Edge<CSCallSite, CSMethod> edge) { if (/* edge target is a taint source method */) { Obj taint = ... // generate taint object // add it to points-to set of LHS variable of the call site solver.addPointsTo(context, lhs, heapContext, taint); } } @Override public void onFinish() { // collect detected taint flows and report them } } -
Activate your analysis plugin.
Analysis plugins are loaded via reflection, so that you do not need to modify existing code to integrate the plugin. Simply add the plugin class name to the plugins option of pointer analysis to turn it on:
... -a pta=plugins:[my.example.TaintAnalysis];...That’s it! Your taint analysis will run together with the pointer analysis.
8. Publications
-
Tian Tan and Yue Li. Tai-e: A Developer-Friendly Static Analysis Framework for Java by Harnessing the Good Designs of Classics. In Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, Seattle, WA, USA. July 17—21, 2023 (ISSTA'23).
-
Wenjie Ma, Shengyuan Yang, Tian Tan, Xiaoxing Ma, Chang Xu and Yue Li. Context Sensitivity without Context: A Cut-Shortcut Approach to Fast and Precise Pointer Analysis. In Proceedings of the ACM on Programming Languages, 2023 (PLDI'23).
-
Tian Tan, Yue Li, Xiaoxing Ma, Chang Xu, and Yannis Smaragdakis. Making Pointer Analysis More Precise by Unleashing the Power of Selective Context Sensitivity. In Proceedings of the ACM on Programming Languages, 2021 (OOPSLA'21).
-
Yue Li, Tian Tan, Anders Møller, and Yannis Smaragdakis. A Principled Approach to Selective Context Sensitivity for Pointer Analysis. ACM Transactions on Programming Languages and Systems, 2020 (TOPLAS'20).
-
Yue Li, Tian Tan, and Jingling Xue. Understanding and Analyzing Java Reflection. ACM Transactions on Software Engineering and Methodology, 2019 (TOSEM'19).
-
Yue Li, Tian Tan, Anders Møller, and Yannis Smaragdakis. Scalability-First Pointer Analysis with Self-Tuning Context-Sensitivity. In Proceedings of the 2018 ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Lake Buena Vista, FL, USA, November 04-09, 2018 (ESEC/FSE'18).
-
Yue Li, Tian Tan, Anders Møller, and Yannis Smaragdakis. Precision-Guided Context Sensitivity for Pointer Analysis. Proceedings of the ACM on Programming Languages, 2018 (OOPSLA'18).
-
Tian Tan, Yue Li, and Jingling Xue. Efficient and Precise Points-to Analysis: Modeling the Heap by Merging Equivalent Automata. In Proceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation, Barcelona, Spain, June 18-23, 2017 (PLDI'17).
-
Tian Tan, Yue Li, and Jingling Xue. Making k-Object-Sensitive Pointer Analysis More Precise with Still k-Limiting. In 23rd International Static Analysis Symposium, Edinburgh, UK, September 8-10, 2016, Proceedings (SAS'16).
-
Yue Li, Tian Tan, Yifei Zhang, and Jingling Xue. Program Tailoring: Slicing by Sequential Criteria. In Proceeding of 30th European Conference on Object-Oriented Programming, July 18-22, 2016, Rome, Italy (ECOOP'16).
-
Yue Li, Tian Tan, and Jingling Xue. Effective Soundness-Guided Reflection Analysis. In 22nd International Static Analysis Symposium, Saint-Malo, France, September 9-11, 2015, Proceedings (SAS'15).
-
Yue Li, Tian Tan, Yulei Sui, and Jingling Xue. Self-Inferencing Reflection Resolution for Java. In 28th European Conference, Uppsala, Sweden, July 28 * August 1, 2014. Proceedings (ECOOP'14).