实验作业 3
作业 3:死代码检测
1 作业导览
- 为 Java 实现一个死代码(dead code)检测算法。
从程序中去除死代码是一种常见的编译优化策略。其中最困难的问题是如何检测到程序中的死代码。在这次的实验作业中,你将会通过组合你前两次作业中实现的分析方法:活跃变量分析和常量传播,来实现一个 Java 的死代码检测算法。在本文档中,我们将会明确界定本次作业中所讨论的死代码的范畴,你的任务就是实现一个检测算法识别它们。
在阅读接下来的内容前,请先按照 Tai-e 框架(教学版)配置指南 将作业 3 对应的 Tai-e 项目(位于实验作业仓库的 A3/tai-e/ )配置好。
2 死代码检测介绍
死代码指的是程序中不可达的(unreachable)代码(即不会被执行的代码),或者是执行结果永远不会被其他计算过程用到的代码。去除死代码可以在不影响程序输出的前提下简化程序、提高效率。在本次作业中,我们只关注两种死代码:不可达代码(unreachable code)和无用赋值(dead assignment)。
2.1 不可达代码
一个程序中永远不可能被执行的代码被称为不可达代码。我们考虑两种不可达代码:控制流不可达代码(control-flow unreachable code)和分支不可达代码(unreachable branch)。这两种代码的介绍如下。
控制流不可达代码. 在一个方法中,如果不存在从程序入口到达某一段代码的控制流路径,那么这一段代码就是控制流不可达的。比如,由于返回语句是一个方法的出口,所以跟在它后面的代码是不可达的。例如在下面的代码中,第 4 行和第 5 行的代码是控制流不可达的:
int controlFlowUnreachable() {
int x = 1;
return x;
int z = 42; // control-flow unreachable code
foo(z); // control-flow unreachable code
}
检测方式:这样的代码可以很简单地利用所在方法的控制流图(CFG,即 control-flow graph)检测出来。我们只需要从方法入口开始,遍历 CFG 并标记可达语句。当遍历结束时,那些没有被标记的语句就是控制流不可达的。
分支不可达代码. 在 Java 中有两种分支语句:if 语句和 switch 语句。它们可能会导致分支不可达代码的出现。
对于一个 if 语句,如果它的条件值(通过常量传播得知)是一个常数,那么无论程序怎么执行,它两个分支中的其中一个分支都不会被走到。这样的分支被称为不可达分支。该分支下的代码也因此是不可达的,被称为分支不可达代码。如下面的代码片段所示,由于第 3 行 if 语句的条件是永真的,所以它条件为假时对应的分支为不可达分支,该分支下的代码(第 6 行)是分支不可达代码。
int unreachableIfBranch() {
int a = 1, b = 0, c;
if (a > b)
c = 2333;
else
c = 6666; // unreachable branch
return c;
}
对于一个 switch 语句,如果它的条件值是一个常数,那么不符合条件值的 case 分支就可能是不可达的。如下面的代码片段所示,第 3 行 switch 语句的条件值(变量 x 的值)永远是 2 ,因此分支 “case 1” 和 “default” 是不可达的。注意,尽管分支 “case 3” 同样没法匹配上条件值(也就是 2),但它依旧是可达的,因为控制流可以从分支 “case 2” 流到它。
int unreachableSwitchBranch() {
int x = 2, y;
switch (x) {
case 1: y = 100; break; // unreachable branch
case 2: y = 200;
case 3: y = 300; break; // fall through
default: y = 666; // unreachable branch
}
return y;
}
检测方式:为了检测分支不可达代码,我们需要预先对被检测代码应用常量传播分析,通过它来告诉我们条件值是否为常量,然后在遍历 CFG 时,我们不进入相应的不可达分支。
2.2 无用赋值
一个局部变量在一条语句中被赋值,但再也没有被该语句后面的语句读取,这样的变量和语句分别被称为无用变量(dead variable,与活跃变量 live variable 相对)和无用赋值。无用赋值不会影响程序的输出,因而可以被去除。如下面的代码片段所示,第 3 行和第 5 行的语句都是无用赋值。
int deadAssign() {
int a, b, c;
a = 0; // dead assignment
a = 1;
b = a * 2; // dead assignment
c = 3;
return c;
}
检测方式:为了检测无用赋值,我们需要预先对被检测代码施用活跃变量分析。对于一个赋值语句,如果它等号左侧的变量(LHS 变量)是一个无用变量(换句话说,not live),那么我们可以把它标记为一个无用赋值。
但需要注意的是,以上讨论有一种例外情况:有时即使等号左边的变量 x 是无用变量,它所属的赋值语句 x = expr 也不能被去除,因为右边的表达式 expr 可能带有某些副作用。例如,当 expr 是一个方法调用(x = m())时,它就有可能带有副作用。对于这种情况,我们提供了一个 API 供你检查等号右边的表达式是否可能带有副作用(在第 3.2 节说明)。如果带有副作用,那么为了保证 safety,即使 x 不是一个活跃变量,你也不应该把这个赋值语句标记为死代码。
3 实现死代码检测器
3.1 Tai-e 中你需要了解的类
为了实现死代码检测算法,你需要知道 CFG,IR,还有其他与活跃变量分析、常量传播分析结果有关的类(比如 CPFact,DataflowResult 等),不过你已经在之前的作业中使用过了它们,应该对它们很熟悉了!接下来我们介绍更多本次作业中将会用到的和 CFG 以及 IR 有关的类。
pascal.taie.analysis.graph.cfg.Edge这个类表示 CFG 中的边(提示:CFG 中的节点是
Stmt)。它具有方法getKind(),可以用来得知某个边的种类(你可以通过阅读类Edge.Kind的注释来理解各个种类的含义),并且你可以像下面这样检查边的种类:Edge<Stmt> edge = ...; if (edge.getKind() == Edge.Kind.IF_TRUE) { ... }在这次作业中,你需要考虑四种边:
IF_TRUE、IF_FALSE、SWITCH_CASE和SWITCH_DEFAULT。IF_TRUE和IF_FALSE表示从 if 语句到它的两个分支的出边,就像下面的例子所示: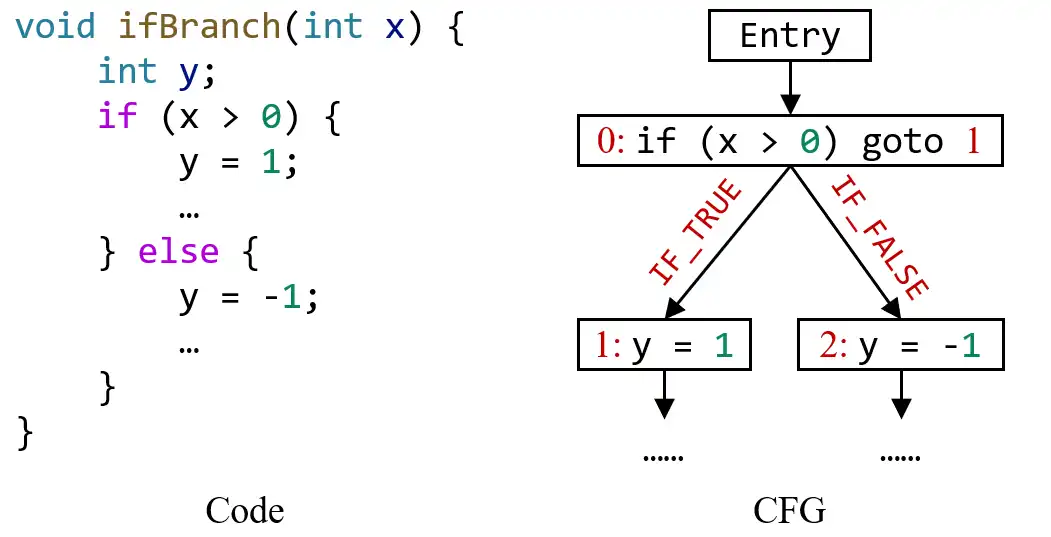
SWITCH_CASE和SWITCH_DEFAULT表示从 switch 语句到它的 case 分支和 default 分支的出边,就像下面的例子所示: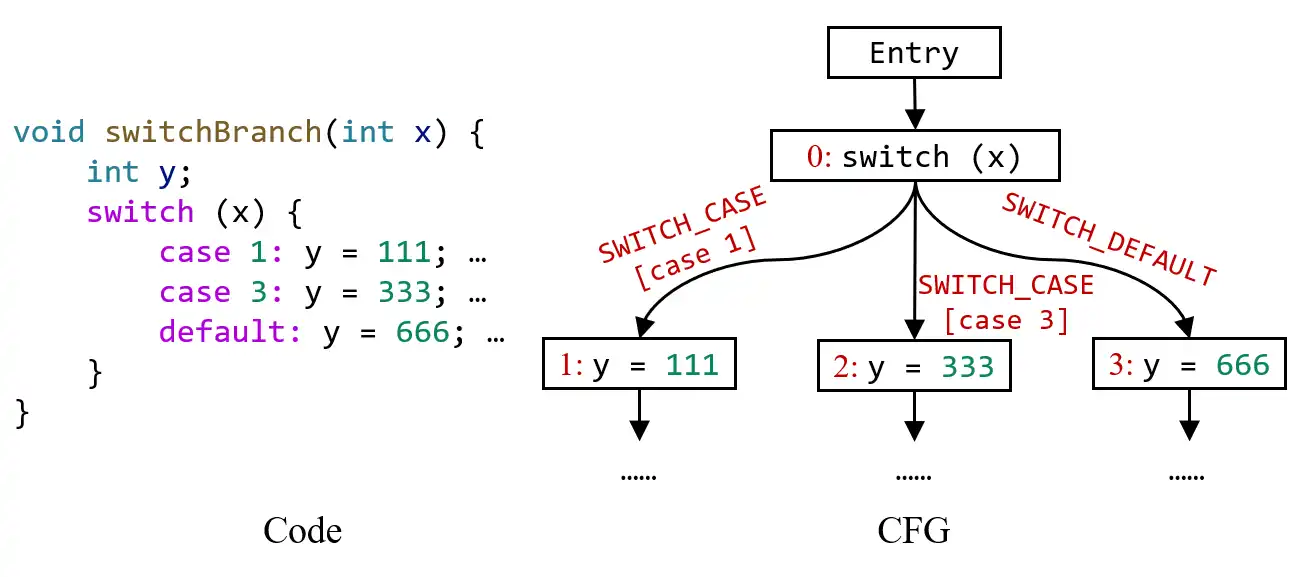
对于
SWITCH_CASE边,你可以通过getCaseValue()方法来获取它们对应的 case 分支的条件值(比如在上面的例子中,调用 case 1 对应的出边的getCaseValue()方法会返回值1,调用 case 3 对应的 out edge 的getCaseValue()方法会返回值3)。pascal.taie.ir.stmt.If(Stmt的子类)这个类表示程序中的 if 语句。
值得注意的是,在 Tai-e 的 IR 中,while 循环和 for 循环也被转换成了
If语句。比如下面这个用 Java 写的循环:while (a > b) { x = 233; } y = 666;在 Tai-e 中将会被转化成像这样的 IR:
0: if (a > b) goto 2; 1: goto 4; 2: x = 233; 3: goto 0; 4: y = 666;因此,你的算法实现不需多加改变就能自然而然地支持检测与循环相关的死代码。比如,如果
a和b都是常量并且a <= b,那么你的分析算法应该把语句x = 233标记成死代码。pascal.taie.ir.stmt.SwitchStmt(Stmt的子类)这个类表示程序中的 switch 语句。你需要阅读它的源代码和注释来决定如何使用它。
pascal.taie.ir.stmt.AssignStmt(Stmt的子类)这个类表示程序中的赋值语句(比如
x = ...;)。你可能会觉得它有点像你之前看到过的DefinitionStmt。下面的部分的类继承关系图展示了这两个类的关系: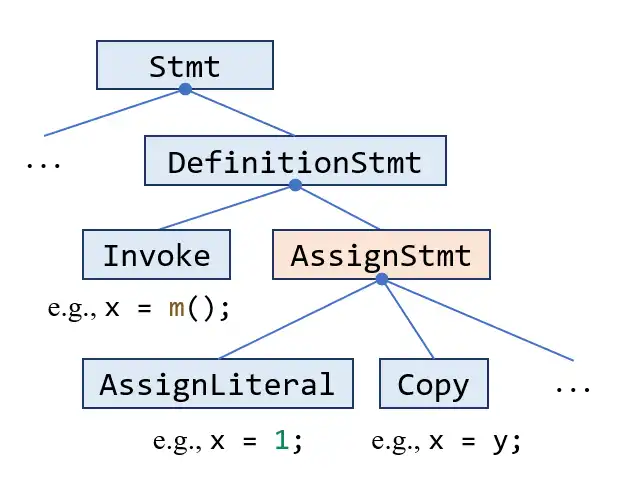
事实上,
AssignStmt是DefinitionStmt两个子类的其中一个(另一个是Invoke,它表示程序中的方法调用)。这意味着除了等号右侧是方法调用的赋值语句,其他赋值语句都用AssignStmt表示。正如第 2.2 节所说的,方法调用可能含有很多副作用,因此对于像x = m();这样的语句,即使x之后再也不会被用到(换言之,x是无用变量),这条语句也不会被认为是无用赋值。因此,本次作业中所有可能的无用赋值都只可能是AssignStmt的实例。你只需要关注AssignStmt这个类即可。pascal.taie.analysis.dataflow.analysis.DeadCodeDetection这个类是实现死代码检测的类。你需要根据第 3.2 节的指导来补完它。
3.2 你的任务 [重点!]
你需要完成 DeadCodeDetection 中的一个API:
- Set<Stmt> analyze(IR)
这个方法将一个 IR 作为输入,返回一个包含 IR 中死代码的集合。你的任务是找出第 2 节中描述的两种死代码(也就是不可达代码和无用赋值),然后将它们加入到作为结果返回的集合中。 为了简单起见,你不需要考虑由删除死代码而产生的新的死代码。就拿我们前面在介绍无用赋值时用过的例子来说,当下列代码中第 3 行和第 5 行的无用赋值被删除后,第 4 行的 a = 1 会变成新的无用赋值,只不过在本次作业中,你不必把它识别为死代码(即不加入到结果集中)。
int deadAssign() {
int a, b, c;
a = 0; // dead assignment
a = 1;
b = a * 2; // dead assignment
c = 3;
return c;
}
死代码检测依赖活跃变量分析和常量传播分析的结果。因此,为了让死代码检测能跑起来,你需要先补全 LiveVariableAnalysis.java 和 ConstantPropagation.java。你可以拷贝你之前作业中的实现。另外,你也需要完成一个同时支持前向分析和后向分析的 worklist 求解器。你可以从作业 2 中拷贝你之前对 Solver.java 和 WorkListSolver.java 的实现,并在这次作业中实现 Solver.initializeBackward()和 WorkListSolver.doSolveBackward()。不过不用担心,这次作业中我们不会要求你提交这些代码的源文件,所以即使你之前作业中的实现并不是完全正确的,它们也不会影响你本次作业的分数。
提示:
- 在这次作业中,Tai-e 会在运行死代码检测之前自动运行活跃变量分析和常量传播分析。我们在
DeadCodeDetection.analyze()中提供了用来获得这两种分析算法针对目标IR的分析结果,这样你可以直接使用它们。另外,analyze()方法包含获取IR的CFG的代码。 - 正如第 2.2 节提到的那样,某些赋值语句等号右侧的表达式可能含有副作用,因此不能被当作 dead assignments。我们在
DeadCodeDetection中提供了一个辅助方法hasNoSideEffect(RValue),用来帮助你检查一个表达式是否含有副作用。 - 在遍历 CFG 时,你需要对当前正在访问的节点使用
CFG.getOutEdgesOf()来帮助获得之后要被访问的后继节点。这个 API 返回给定节点在 CFG 上的出边,所以你可以用边的信息(在第 3.1 节介绍过)来帮助找出分支不可达代码。 - 当在寻找分支不可达代码时,你可以使用
ConstantPropagation.evaluate()来计算 if 和 switch 语句的条件值。
4 运行与测试
你可以参考 Tai-e 框架(教学版)配置指南 来运行分析算法。在这次作业中,Tai-e 为输入的类中的每一个方法运行活跃变量分析、常量传播分析和死代码检测算法。为了帮助调试,它会如下输出三个分析算法的结果:
当未完成这三个分析算法的时候,OUT facts 都为 null,并且没有代码被标记为死代码。在你完成了三个分析算法后,输出应当形如:
此外,Tai-e 会把它分析的目标方法的控制流图输出到文件夹 output/ 里。CFGs 会被存储成 .dot 文件,并且可以通过 Graphviz 可视化。
我们为这次作业提供了测试驱动 pascal.taie.analysis.dataflow.analysis.DeadCodeTest。你可以按照 Tai-e 框架(教学版)配置指南 所介绍的那样使用它来测试你的实现。
5 通用准则
在这次作业中,你只需要保证实现的正确性。不必过早考虑效率。
禁止把你的作业包发给其他人参考。
禁止抄袭。自己的工作必须由自己完成。
6 作业提交
你应当提交一个 zip 文件,其中包括你实现好的以下类:
DeadCodeDetection.java
7 评分
你可以参照 实验作业评测系统使用指南 来使用我们的作业评测系统对你完成的作业进行评分。
你的分数将取决于你实现的正确性:我们会用你提交的实现来分析 src/test/resources/ 目录下的测试用例和另外一些未公开的测试用例,然后将得到的结果与标准实现的分析结果比较,从而进行评分。
祝君好运!